RAG(검색 증강 생성)에 대한 짧은 정리
Future of LLM 을 우리 제품에 녹여내기
‘검색 증강 생성’ 이라 불리는 RAG(Retrieval Augmented Generation) 에 대해 최근 호기심이 생겨 찾아본 내용을 정리해본다. OpenAI 의 ChatGPT 를 필두로 많은 회사들이 LLM 을 상용화하며 AI 업계의 판도가 바뀌었고, 업계에서 AI 개발을 접근하는 방향도 많이 바뀌었다. 모델을 직접 학습, 개발하던 방식에서 LLM 을 최대한으로 활용하는 방식으로 말이다.
LLM 의 한계를 넘어서
ChatGPT 출시 당시 많은 사용자에게 신선한 충격을 주며 그 활용성이 무한해보였는데 이후로 많은 단점들이 드러났다. 단점들 중에서는 사실 관계의 오류나 사용자 질문의 맥락을 이해하는데 한계점을 보인다는 점이 있다. 이에 대한 개선으로 RAG 가 떠오르고 있다고 한다. ‘LLM 의 미래’ 라고 불리고 있는 RAG 는 외부 지식 베이스를 연결하여 언어 모델의 능력을 향상시키는 기술이다.
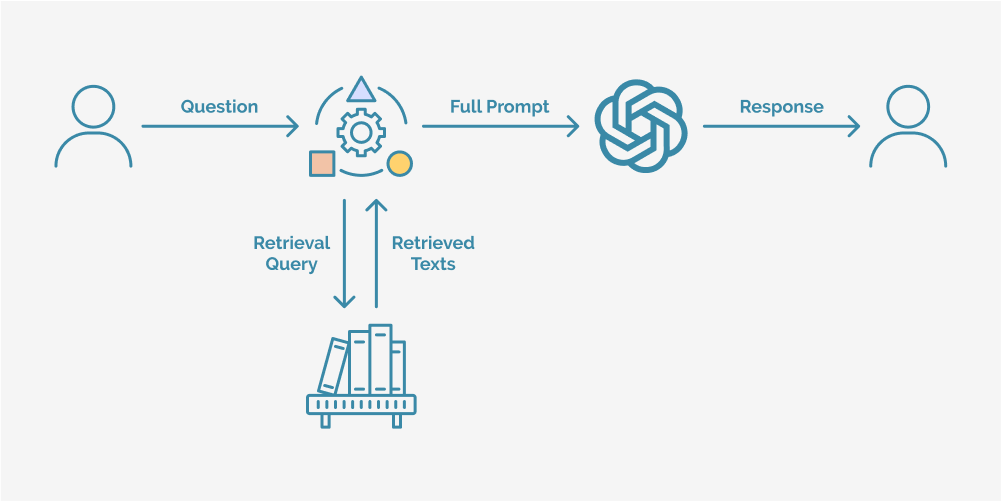 RAG - https://www.trantorinc.com/blog/what-is-rag-retrieval-augmented-generation
RAG - https://www.trantorinc.com/blog/what-is-rag-retrieval-augmented-generation
LLM 이 응답하기 이전 벡터 DB 에 저장된 데이터에서 관련 정보 추출하고, 이후 사용자의 쿼리와 벡터 DB 에서 Retrieve 한 데이터를 바탕으로 최종 답변 생성한다.
RAG 활용한 개발
현재 진행되는 개발은 LangChain 을 활용 중이다. 랭체인은 LLM 을 활용하여 애플리케이션을 개발 시에 사용하는 프레임워크이다. LangChain 의 Agent 가 LLM 과 다른 데이터 소스 등 두 가지 이상 조합을 가능하게 하는데, 여기서 활용할 데이터 소스가 위에 언급한 벡터 DB 가 될 것이다. 참고로, LangSmith 는 LangChain 으로 만든 애플리케이션의 성능을 모니터링, 최적화하는 도구로 유지보수에 사용된다.
현재 팀에서 관심을 갖고 있는 것은 챗봇 개발인데, RAG 를 활용하기 가장 좋은 주제로 생각된다. 기존 LLM 에서 제공할 수 없었던 우리 회사 제품에 대한 정보를, 벡터 DB 에서 가져와 그 context 를 가지고 우리의 어플리케이션 사용자가 질의한 쿼리를 답변할 수 있을 것으로 기대한다.
참고
- https://www.trantorinc.com/blog/what-is-rag-retrieval-augmented-generation
- https://www.ncloud-forums.com/topic/277